RankIQA-论文笔记
RankIQA

主要思想:
Hinge Loss(折页损失函数,铰链损失)

L(y) = max(0 , 1 – t⋅y)
其中,y是预测值(-1到1之间),t为目标值(1或 -1)。其含义为,y的值在 -1到1之间即可,并不鼓励 |y|>1,即让某个样本能够正确分类就可以了,不鼓励分类器过度自信,当样本与分割线的距离超过1时并不会有任何奖励。目的在于使分类器更专注于整体的分类误差。在实际应用中,一方面,预测值y并不总是属于[-1,1],也可能属于其他的取值范围;另一方面,很多时候我们希望训练的是两个元素之间的相似关系,而非样本的类别得分。所以下面的公式可能会更加常用:
L( y, y′) = max( 0, margin – (y–y′) )
= max( 0, margin + (y′–y) )
= max( 0, margin + y′ – y)
其中,y是正确预测的得分,y′是错误预测的得分,两者的差值可用来表示两种预测结果的相似关系,margin是一个由自己指定的安全系数。我们希望正确预测的得分高于错误预测的得分,且高出一个边界值 margin,换句话说,y越高越好,y′ 越低越好,(y–y′)越大越好,(y′–y)越小越好,但二者得分之差最多为margin就足够了,差距更大并不会有任何奖励。这样设计的目的在于,对单个样本正确分类只要有margin的把握就足够了,更大的把握则不必要,过分注重单个样本的分类效果反而有可能使整体的分类效果变坏。分类器应该更加专注于整体的分类误差。
举个栗子,假设有3个类cat、car、frog:

第一列表示样本真实类别为cat,分类器判断样本为cat的分数为3.2,判断为car的分数为5.1,判断为frog的分数为 -1.7。那这里的 hinge loss 怎么计算呢?
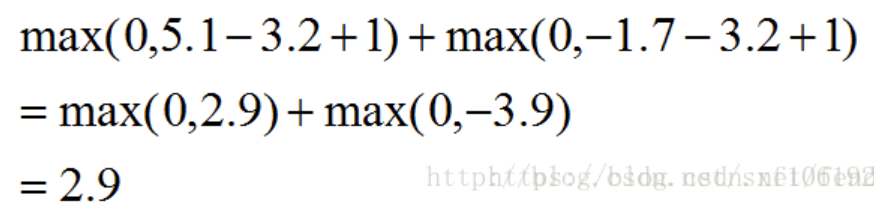
这里是让其他两类的分数去减去真实类别的分数,这相当于计算其他类与真实类之间的误差。因为我们希望错误类别的评分低于正确类别的评分,所以这个误差值越小越好。另外,还使用了一个边界值margin,取值为1,为了使训练出的分类器有更大的把握进行正确分类。
有多种 hinge loss 的变化形式,比如,Crammerand Singer提出的一种针对线性分类器的损失函数:

Weston and Watkins提出了一种相似定义,只不过用相加取代了求最大值:


Efficient Siamese backpropagation:
在反向传播阶段,对于模型参数的更新作者并未采用随机梯度下降算法而是采用了批梯度下降算法,这样一来假如我们所设置的batch-size为n那我们就可以先进行n次的正向传播完成这一batch中所有图像的处理之后再根据他们的处理结果计算hinge损失并求得均值进行反向传播。这样一来一个batch中的图片每张都只需要进行1次正向处理就可以与其余的n-1张图片完成对比,极大地降低了计算成本同时也有效保证了更新的有效性。此外在进行梯度计算时,作者采用了矩阵计算,利用GPU也极大地提升了运算效率。



评论
发表评论