Attention is all you need
Transformer

Part 1 Multihead Attention and the self attention

以图中的token a2为例:
- 它产生一个query,每个query都去和别的token的key做“某种方式”的计算,得到的结果我们称为attention score(即为图中的
)。则一共得到四个attention score(attention score又可以被称为attention weight)。
- 将这四个score分别乘上每个token的value,我们会得到四个抽取信息完毕的向量。
- 将这四个向量相加,就是最终a2过attention模型后所产生的结果b2。
- 下图描述了产生query(q),key(k)和value(v)的过程:


总结一下,到目前为止,对于某条输入序列X,我们有:
现在,我们做两件事:
- 利用Q和K,计算出attention score矩阵,这个矩阵由图3中的
- 利用V和attention score矩阵,计算出Attention层最终的输出结果矩阵,这个矩阵由图3中的b组成。
记最终的输出结果为 ,则有:
这个 就是k_dim,而
就是Attention Score矩阵,我们来详细看下这个矩阵的计算过程。

更确切地说,论文中所采用的是scaled dot-product,因为乘上了因子 。在softmax之后,attention score矩阵的每一行表示一个token,每一列表示该token和对应位置token的
值,因为进行了softmax,每一行的
值相加等于1。

之所以进行scaling,是为了使得在softmax的过程中,梯度下降得更加稳定,避免因为梯度过小而造成模型参数更新的停滞。下面我们通过数学证明,来解释这个结论。为了表达方便(也为了和论文的标识保持一致),我们把k_dim写成 ,同理v_dim写成
,S表示softmax函数,假设在做softmax之前,紫色矩阵里的每一个值为
,则有:
聚焦到紫色矩阵的某一行,对于其中某个 ,我们有:
从上面可以看出:
- 当
相对于同一行其他的
更大的时候,
趋近于1,
趋近于0,此时以上的两个结果都趋近于0。
- 当
总结起来,即当 相对于其他结果过大或者过小时,都会造成softmax函数的偏导趋近于0(梯度过低)。在这种情况下,整个模型在backprop的过程中,经过softmax之后,就无法继续传播到softmax之前的函数上,造成模型参数无法更新,影响了模型的训练效率。
那么 是怎么计算来的呢?通过前面的讲解可以知道:
假设向量q和k中的每一个元素都是相互独立,均值为0,方差为1的随机变量,那么易知 的均值也为0,方差为
。
较大,意味着不同
间值的差距也很大,这就导致了上面所说的梯度消失的问题。
Masked attention:
有时候,我们并不想在做attention的时候,让一个token看到整个序列,我们只想让它看见它左边的序列,而要把右边的序列遮蔽(Mask)起来。例如在transformer的decoder层中,我们就用到了masked attention,这样的操作可以理解为模型为了防止decoder在解码encoder层输出时“作弊”,提前看到了剩下的答案,因此需要强迫模型根据输入序列左边的结果进行attention。
Masked的实现机制其实很简单,如图:
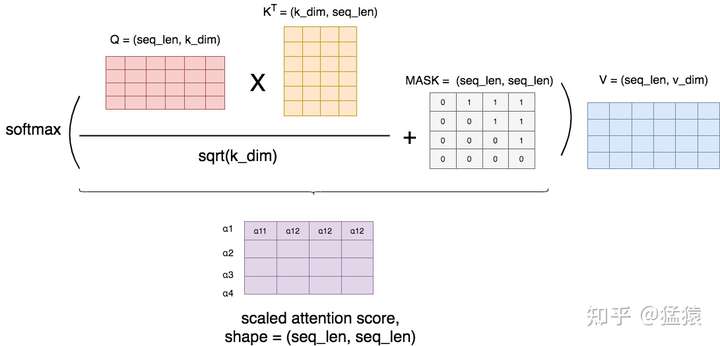
首先,我们按照前文所说,正常算attention score,然后我们用一个MASK矩阵去处理它(这里的+号并不是表示相加,只是表示提供了位置覆盖的信息)。在MASK矩阵标1的地方,也就是需要遮蔽的地方,我们把原来的值替换为一个很小的值(比如-1e09),而在MASK矩阵标0的地方,我们保留原始的值。这样,在进softmax的时候,那些被替换的值由于太小,就可以自动忽略不计,从而起到遮蔽的效果。
举例来说明MASK矩阵的含义,每一行表示对应位置的token。例如在第一行第一个位置是0,其余位置是1,这表示第一个token在attention时,只看到它自己,它右边的tokens是看不到的。以此类推。
Multihead Attention:
在图像中,我们知道有不同的channel,每一个channel可以用来识别一种模式。如果我们对一张图采用attention,比如把这张图的像素格子拉平成一列,那么我们可以对每个像素格子训练不同的head,每个head就类比于一个channel,用于识别不同的模式。
而在NLP中,这种模式识别同样重要。比如第一个head用来识别词语间的指代关系(某个句子里有一个单词it,这个it具体指什么呢),第二个head用于识别词语间的时态关系(看见yesterday就要用过去式)等等。
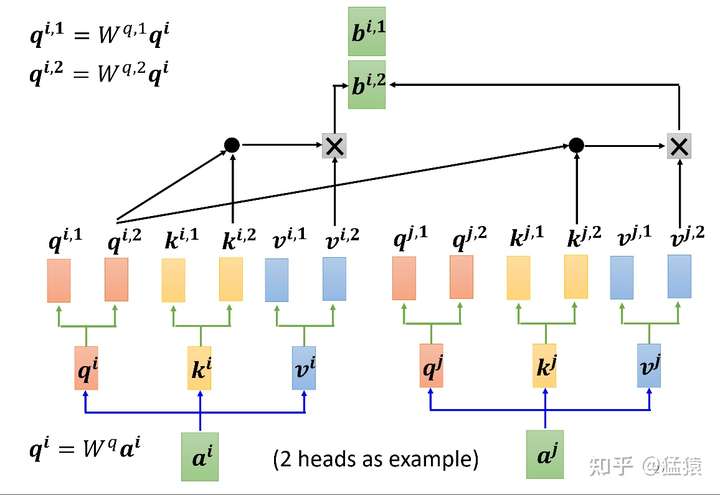
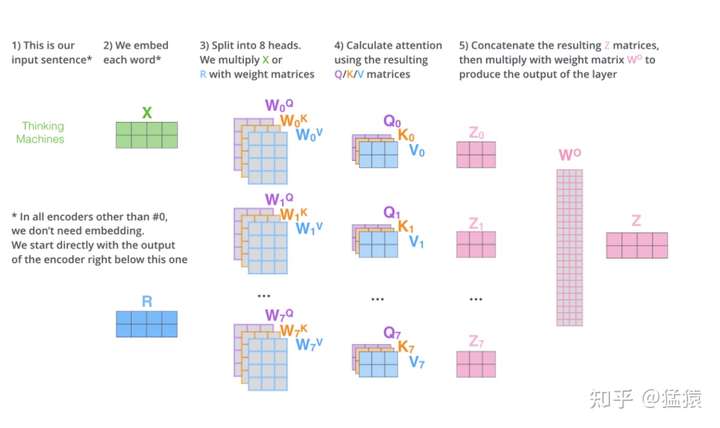
下图,图8展示了multihead attention的运作方式。设头的数量为num_heads,那么本质上,就是训练num_heads个 个矩阵,用于生成num_heads个
结果。每个结果的计算方式和单头的attention的计算方式一致。最终将生成的b连接起来生成最后的结果。图9详细展示了8个head的矩阵化的运算过程,由于拆分成了多头,则此时有
也就是说, 的维度变为
。按照这个规则拆分后,多头的运算量和原来单头的运算量一样。同时在图9中,在输出部分出现了一个
矩阵,这个矩阵用于将拼接起来的多头输出转换为最终总输出
将每个head上的attention score分数打出,可以具象化地感受每个head的关注点,以入句子"The animal didn't cross the street because it was too tired"为例,可视化代码可点此(存在Google colab上,需要翻墙)。

如图10,颜色越深表示attention score越大,我们构造并连接五层的attention模块,可以发现it和animal,street关系密切。现在我们把8个头全部加上去,参见图11。

如图11,一种颜色表示一个头下attention score的分数,可以看出,不同的头所关注的点各不相同。
Positional Encoding
一、什么是位置编码
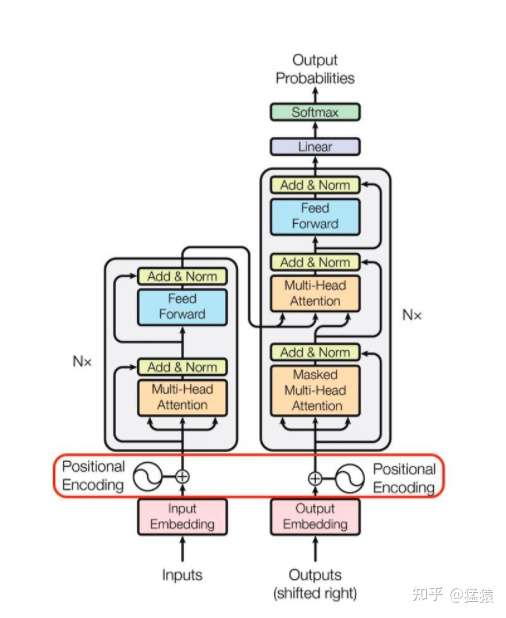
在transformer的encoder和decoder的输入层中,使用了Positional Encoding,使得最终的输入满足:
这里,input_embedding是通过常规embedding层,将每一个token的向量维度从vocab_size映射到d_model,由于是相加关系,自然而然地,这里的positional_encoding也是一个d_model维度的向量。(在原论文里,d_model = 512)
那么,我们为什么需要position encoding呢?在transformer的self-attention模块中,序列的输入输出如下(不了解self-attention没关系,这里只要关注它的输入输出就行):
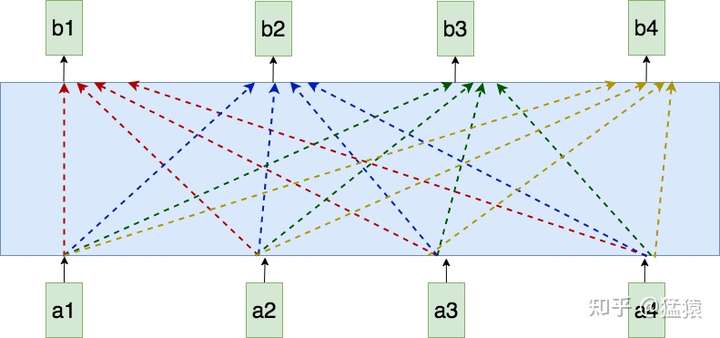
在self-attention模型中,输入是一整排的tokens,对于人来说,我们很容易知道tokens的位置信息,比如:
(1)绝对位置信息。a1是第一个token,a2是第二个token......
(2)相对位置信息。a2在a1的后面一位,a4在a2的后面两位......
(3)不同位置间的距离。a1和a3差两个位置,a1和a4差三个位置....
但是这些对于self-attention来说,是无法分辩的信息,因为self-attention的运算是无向的。因为,我们要想办法,把tokens的位置信息,喂给模型。
二、构造位置编码的方法 /演变历程
2.1 用整型值标记位置
一种自然而然的想法是,给第一个token标记1,给第二个token标记2...,以此类推。
这种方法产生了以下几个主要问题:
(1)模型可能遇见比训练时所用的序列更长的序列。不利于模型的泛化。
(2)模型的位置表示是无界的。随着序列长度的增加,位置值会越来越大。
2.2 用[0,1]范围标记位置
为了解决整型值带来的问题,可以考虑将位置值的范围限制在[0, 1]之内,其中,0表示第一个token,1表示最后一个token。比如有3个token,那么位置信息就表示成[0, 0.5, 1];若有四个token,位置信息就表示成[0, 0.33, 0.69, 1]。
但这样产生的问题是,当序列长度不同时,token间的相对距离是不一样的。例如在序列长度为3时,token间的相对距离为0.5;在序列长度为4时,token间的相对距离就变为0.33。
因此,我们需要这样一种位置表示方式,满足于:
(1)它能用来表示一个token在序列中的绝对位置
(2)在序列长度不同的情况下,不同序列中token的相对位置/距离也要保持一致
(3)可以用来表示模型在训练过程中从来没有看到过的句子长度。
2.3 用二进制向量标记位置
考虑到位置信息作用在input embedding上,因此比起用单一的值,更好的方案是用一个和input embedding维度一样的向量来表示位置。这时我们就很容易想到二进制编码。如下图,假设d_model = 3,那么我们的位置向量可以表示成:
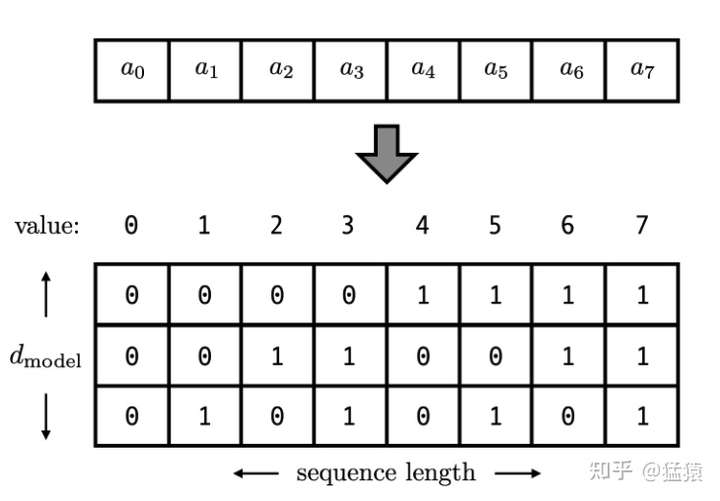
这下所有的值都是有界的(位于0,1之间),且transformer中的d_model本来就足够大,基本可以把我们要的每一个位置都编码出来了。
但是这种编码方式也存在问题:这样编码出来的位置向量,处在一个离散的空间中,不同位置间的变化是不连续的。假设d_model = 2,我们有4个位置需要编码,这四个位置向量可以表示成[0,0],[0,1],[1,0],[1,1]。我们把它的位置向量空间做出来:
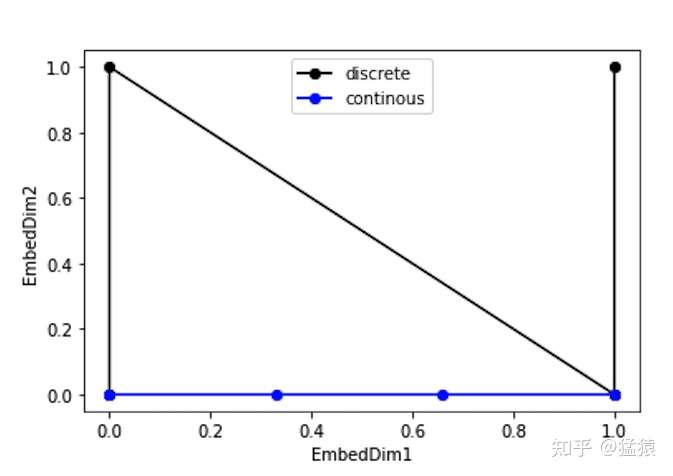
如果我们能把离散空间(黑色的线)转换到连续空间(蓝色的线),那么我们就能解决位置距离不连续的问题。同时,我们不仅能用位置向量表示整型,我们还可以用位置向量来表示浮点型。
2.4 用周期函数(sin)来表示位置
回想一下,现在我们需要一个有界又连续的函数,最简单的,正弦函数sin就可以满足这一点。我们可以考虑把位置向量当中的每一个元素都用一个sin函数来表示,则第t个token的位置向量可以表示为:
结合下图,来理解一下这样设计的含义。图中每一行表示一个 ,每一列表示
中的第i个元素。旋钮用于调整精度,越往右边的旋钮,需要调整的精度越大,因此指针移动的步伐越小。每一排的旋钮都在上一排的基础上进行调整(函数中t的作用)。通过频率
来控制sin函数的波长,频率不断减小,则波长不断变大,此时sin函数对t的变动越不敏感,以此来达到越向右的旋钮,指针移动步伐越小的目的。 这也类似于二进制编码,每一位上都是0和1的交互,越往低位走(越往左边走),交互的频率越慢。
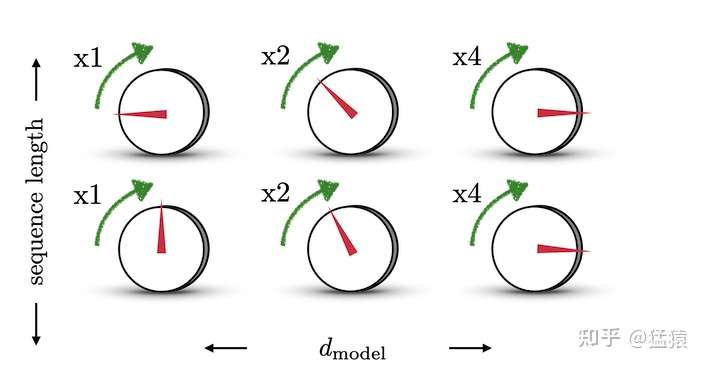

由于sin是周期函数,因此从纵向来看,如果函数的频率偏大,引起波长偏短,则不同t下的位置向量可能出现重合的情况。比如在下图中(d_model = 3),图中的点表示每个token的位置向量,颜色越深,token的位置越往后,在频率偏大的情况下,位置响亮点连成了一个闭环,靠前位置(黄色)和靠后位置(棕黑色)竟然靠得非常近:
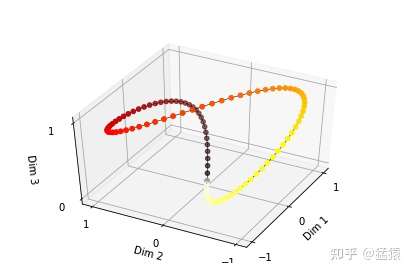
为了避免这种情况,我们尽量将函数的波长拉长。一种简单的解决办法是同一把所有的频率都设成一个非常小的值。因此在transformer的论文中,采用了 这个频率(这里i其实不是表示第i个位置,但是大致意思差不多,下面会细说)
总结一下,到这里我们把位置向量表示为:
其中,
2.5 用sin和cos交替来表示位置
目前为止,我们的位置向量实现了如下功能:
(1)每个token的向量唯一(每个sin函数的频率足够小)
(2)位置向量的值是有界的,且位于连续空间中。模型在处理位置向量时更容易泛化,即更好处理长度和训练数据分布不一致的序列(sin函数本身的性质)
那现在我们对位置向量再提出一个要求,不同的位置向量是可以通过线性转换得到的。这样,我们不仅能表示一个token的绝对位置,还可以表示一个token的相对位置,即我们想要:
这里,T表示一个线性变换矩阵。观察这个目标式子,联想到在向量空间中一种常用的线形变换——旋转。在这里,我们将t想象为一个角度,那么 就是其旋转的角度,则上面的式子可以进一步写成:
有了这个构想,我们就可以把原来元素全都是sin函数的 做一个替换,我们让位置两两一组,分别用sin和cos的函数对来表示它们,则现在我们有:
在这样的表示下,我们可以很容易用一个线性变换,把 转变为
:
三、Transformer中位置编码方法:Sinusoidal functions
3.1 Transformer 位置编码定义
有了上面的演变过程后,现在我们就可以正式来看transformer中的位置编码方法了。
定义:
- t是这个token在序列中的实际位置(例如第一个token为1,第二个token为2...)
- 是这个token的位置向量,
表示这个位置向量里的第i个元素
- 是这个token的维度(在论文中,是512)
则 可以表示为:
这里:
看得有点懵不要紧,这个意思和2.5中的意思是一模一样的,把512维的向量两两一组,每组都是一个sin和一个cos,这两个函数共享同一个频率 ,一共有256组,由于我们从0开始编号,所以最后一组编号是255。sin/cos函数的波长(由
决定)则从
增长到
3.2 Transformer位置编码可视化
下图是一串序列长度为50,位置编码维度为128的位置编码可视化结果:
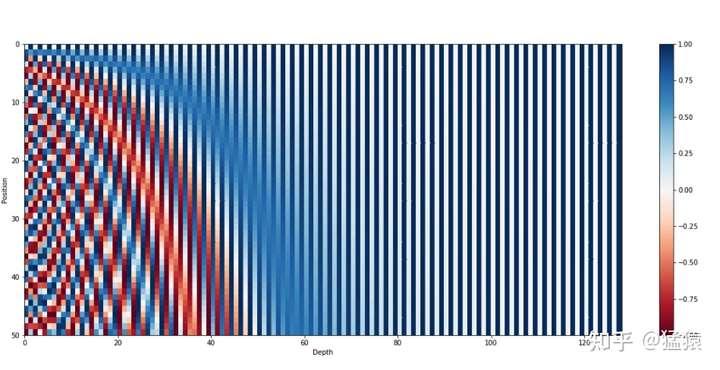
可以发现,由于sin/cos函数的性质,位置向量的每一个值都位于[-1, 1]之间。同时,纵向来看,图的右半边几乎都是蓝色的,这是因为越往后的位置,频率越小,波长越长,所以不同的t对最终的结果影响不大。而越往左边走,颜色交替的频率越频繁。
3.3 Transformer位置编码的重要性质
让我们再深入探究一下位置编码的性质。
(1) 性质一:两个位置编码的点积(dot product)仅取决于偏移量 ,也即两个位置编码的点积可以反应出两个位置编码间的距离。
证明:
(2) 性质二:位置编码的点积是无向的,即
证明:
由于cos函数的对称性,基于性质1,这一点即可证明。
我们可以分别训练不同维度的位置向量,然后以某个位置向量 为基准,去计算其左右和它相距
的位置向量的点积,可以得到如下结果:
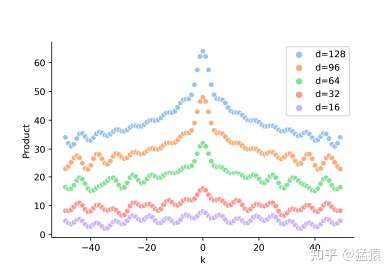
这里横轴的k指的就是 ,可以发现,距离是对成分布的,且总体来说,
越大或者越小的时候,内积也越小,可以反馈距离的远近。也就是说,虽然位置向量的点积可以用于表示距离(distance-aware),但是它却不能用来表示位置的方向性(lack-of-directionality)。
当位置编码随着input被喂进attention层时,采用的映射方其实是:
这里 和
表示self-attention中的query和key参数矩阵,他们可以被简写成
表示attention score的矩阵,到这里看不懂也没事,在self-attention的笔记里会说明的)。我们可以随机初始化两组
,然后将
,
和
这三个内积进行比较,得到的结果如下:
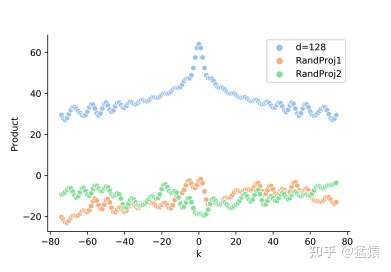
绿色和黄色即是 和
的结果。可以发现,进入attention层之后,内积的距离意识(distance-aware)的模式也遭到了破坏。更详细的细节,可以参见复旦大学这一篇用transformer做NER的论文中。
在Transformer的论文中,比较了用positional encoding和learnable position embedding(让模型自己学位置参数)两种方法,得到的结论是两种方法对模型最终的衡量指标差别不大。不过在后面的BERT中,已经改成用learnable position embedding的方法了,也许是因为positional encoding在进attention层后一些优异性质消失的原因(猜想)。Positional encoding有一些想象+实验+论证的意味,而编码的方式也不只这一种,比如把sin和cos换个位置,依然可以用来编码。关于positional encoding,我也还在持续探索中。



评论
发表评论